Last month I wrote about where automated builds hit their ceiling: costs, reviewer fatigue, and models that are not smart enough for full autonomy. That post ended with “I am more or less at a standstill when it comes to further improvement.” What I meant with that is the quality of the code: a ceiling seems to be reached with that. However that does not mean it is not good enough to actually use for making real products. I have been working on automated workflows for code building for quite some time, and the next step was presenting the whole thing to my colleagues and hearing “can we use this?”
The Pitch
I have been iterating on automated builds for over a year now. Different tools, different approaches, lots of starting over. This evolved into a Go server with a React frontend that could orchestrate Claude Code containers to plan, build, and review code autonomously. It ran on my local server and it worked. I tested it on my own and a few work repos and the output was good: decent quality code and a lot of time saved.
When I showed this to the team, the reaction was “how soon can we plug this into our workflow?” The appeal was straightforward: we can do more with the same team, product owners and domain experts can contribute ideas directly, and we are less dependent on developers for every small change.
Used to Jira
The prototype proved the concept but it was not a fit for company use. It replaced too much: it had its own project management UI, backlog and task board. Nice for my own use, but we already have Jira. We are used to it (not addicted to it), so it seemed a good choice not to change everything at once: do not replace Jira. Everything still works without the LLM layer. Issues get created in Jira the normal way. Developers can pick them up the normal way. The automated builder is an addition, not a replacement.
This matters because nobody had to change how they work on day one. A product owner creates a Jira issue, adds it to the sprint, and if they put it in a specific status column with a specific label the builder picks it up. If the ticket does not have the label, a human developer picks it up instead. Same board, same workflow, one extra option.
I can imagine we move away from Jira eventually. But now is not the right moment. We need to gain experience with this step first, and forcing a tool change at the same time would muddy the results.
How It Works
The system is called Codebuilder for internal use. It polls Jira for issues in a trigger status, spawns Docker containers running Claude Code, and reports results back as comments, status transitions, labels, and pull requests.
Jira (issue moves to trigger status)
|
v
Poller --> Engine --> Docker Container
|
v
Claude Code + build script
|
+-- calls back to Codebuilder API
+-- uses MCP server for project knowledge + Jira
+-- creates draft PR on GitHub
|
v
Container exits --> Engine completes job
|
v
Jira comment + status transition
The worker inside the container does planning and building in one pass. It has access to project knowledge (specifications, requirements, architectural decisions) through an MCP server, and it can read and update the Jira issue it is working on. When it is done, it creates a draft PR. A developer reviews, possibly makes small changes, and merges. The merged PR auto-transitions the Jira issue to done.
Half an hour from “issue in queue” to “PR ready for review.”
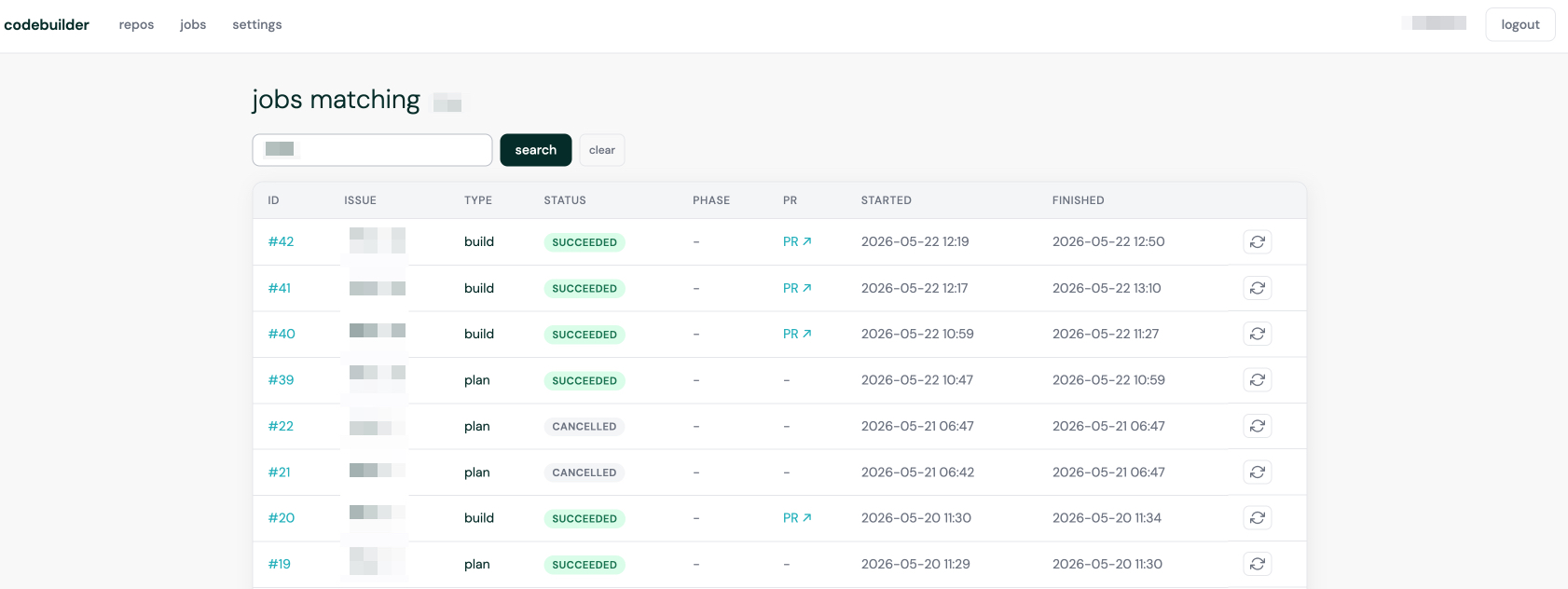
What It Looks Like
In essence there are five steps that run in a single docker container, every step is a new claude code session:
- research
- plan
- build
- review
- fix
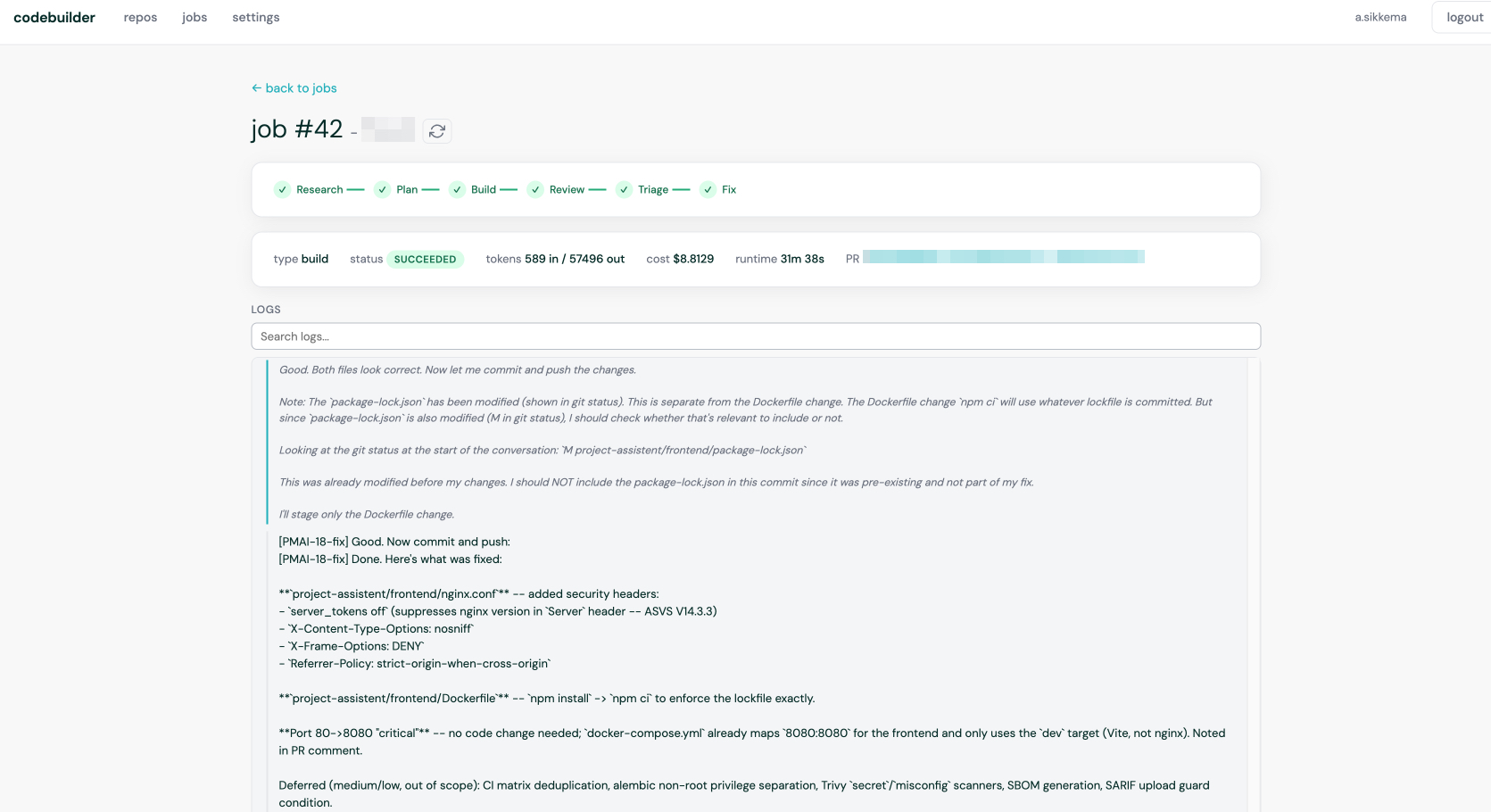
The reason why everything runs in docker containers is mainly security: this isolates claude code from the server, making sure the LLM (which runs unsupervised), has no access to the server. Also we make sure no secrets are available (like a .env file), to minimise risks. This does mean that small errors can be part of the build, but this is acceptable over allowing a very knowledgeable but non-responsible entity roaming around your files.
What we added: Azure AD single sign-on, Axiom for structured logging, Telegram notifications, CSRF protection, rate limiting, and a CLI tool for developers to review and merge automated PRs from their terminal that integrates with the mcp server to make sure github and jira get updated through the cli as well.
Another important one: product owners and others can interact with Jira through Claude Code directly in the browser. We already have the setup to run Claude Code on the server, so by exposing that through a web interface someone can use the full setup without leaving their browser.
This helps tremendously with refining issues and keeping the project up to date. Nothing nicer than asking “what small issues and bugs are there on the backlog that we could combine in one run?” without having to go through a long list yourself.
The Bigger Picture: Not Just for Developers
The part I am most excited about is what this enables for people who are not developers.
The idea: a product owner or domain expert fills out a form describing what they want. That goes into a refinement queue. An LLM (with human oversight) helps refine the idea into a well-scoped issue with acceptance criteria. The refined issue either goes to the automated build queue or gets assigned to a human developer, depending on complexity and judgment.
This is not “non-technical people writing code.” It is non-technical people contributing meaningful input to the development process without needing a developer to translate their ideas into tickets. The LLM handles the translation, a developer or product owner reviews it, and the builder does the implementation.
What Worries Me
Two things, and they are the same ones from my previous post.
Token costs. The quality is high because we run rigorous planning and review cycles, both LLM and human. But the planning and review steps require the best models to maintain a minimum quality bar. Cheaper models produce reviews that miss subtle issues or flag correct code as broken, and bad automated reviews are worse than no reviews because they create false confidence. Token prices keep shifting, and not always downward. That uncertainty makes it hard to forecast costs for the next quarter. In the end it is still cheaper than a purely human review, but the gap is not as large as it used to be.
Developer fatigue. Reviewing LLM-generated code is fundamentally different from writing code yourself. You lose the mental map you build when you write the code. You are reading someone else’s work in a codebase you did not shape, and the entity that wrote it does not learn from your feedback across sessions. After a few hours your attention drops. After a few days you start wondering if this is what the job looks like from now on. I wrote about this before and it is still true, just more visible now that multiple people experience it instead of only me.
Our current answer: all PRs get an automated LLM review as part of the workflow. The developer decides whether to also ask a colleague for a human review. The guideline is to always request one for database changes, large frontend or backend changes, and anything security-related. At first this seems a bit uneasy, not having a second reviewer. However, the automated review is so thorough that it catches more than most (if not all) humans would.
Where We Are Now
We are in the “use it carefully and learn” phase. It works, it is fast, the code quality is good, and it is cheaper than a developer hour. A year ago I started stitching together shell scripts to run Claude Code in sequence. Now a product owner can drop an idea into Jira and get a reviewable PR back before lunch.
There is a lot more to cover: how we handle failures, what the prompts look like, how we scope issues for the builder, token cost breakdowns, and what happens when the model gets it wrong. That will be a follow-up post once we have more production hours under our belt.
Want something like this for your company? I can build it, and it is a lot of fun to do. Get in touch and we will figure out what fits your workflow.
Resources
- Claude Code - Anthropic’s agentic coding CLI
- Model Context Protocol - The protocol Codebuilder uses to expose project knowledge to workers
- Axiom - Structured logging and observability
- Azure AD OIDC - Authentication setup
Related posts
These cover the individual steps and lessons behind Codebuilder in more detail:
- The Orchestrator: Automating Full Claude Code Workflows - The earlier orchestration approach: research, plan, build, review chained together
- When LLMs Actually Deliver - The tooling that makes LLM builds produce usable output
- Human in the Loop: Why Your LLM-Assisted Code Still Needs Human Eyes - Why automated review alone is not enough
- Fully Automated LLM Builds: Where It Actually Stops - Costs, fatigue, and model ceilings at scale
- Why I Shrunk Claude Code’s Context Window Back to 200k - Context management lessons that feed into how workers are configured
- Supercharge Claude Code with Custom Configuration - The agent/skill/hook setup that Codebuilder workers inherit